Introducing Playground v2.5
Daiqing LiAleks KamkoAli SabetSuhail Doshi

Announcing Playground v2.5, our latest text-to-image generative model, available to the public and research community today. Playground v2.5 is the state-of-the-art open-source model in aesthetic quality, with a particular focus on enhanced color and contrast, improved generation for multi-aspect ratios, and improved human-centric fine detail. We have also published a technical report for this model, and you can also find it on HuggingFace.
With this release, we intentionally chose to push the bounds of our current SDXL architecture. While we are excited to explore new architectures in future models, our goal was to quickly deliver improvements to our users (Playground v2 was published in December 2023).
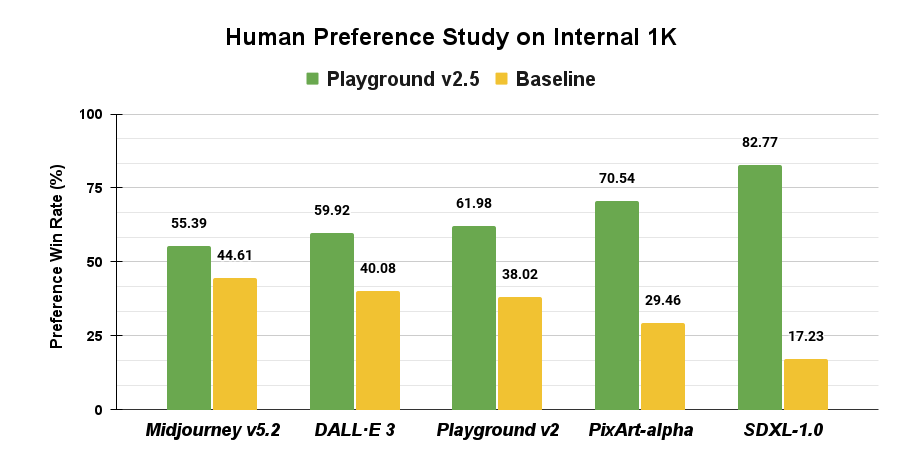
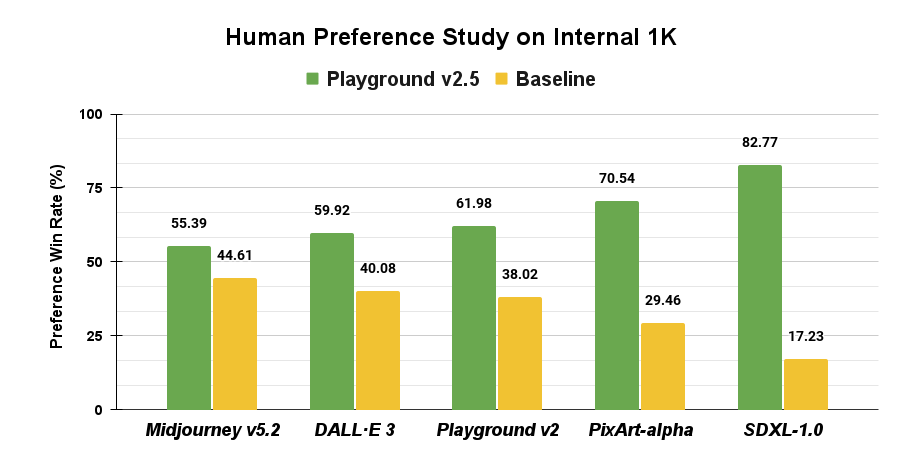
What we found during our research was that a novel set of methods drove a surprisingly significant increase in aesthetic quality, even with the current architecture. Our user studies demonstrate that our model now dramatically outperforms leading open source models like SDXL, Playground v2, and PixArt-⍺, as well as besting closed-source image models like DALL·E 3 and Midjourney v5.2.
This model is available today for anyone to try for free on Playground.com. In fact, we soft-launched v2.5 with a subset of Playground’s users and have been astonished with what they have already created.

Image created by user VVinchi with Playground v2.5

Image created by user PolyCrumbs with Playground v2.5

Image created by Playground user with Playground v2.5

Image created by user Shaddy with Playground v2.5

Image created by user Bella with Playground v2.5
As with our previous model, we have open-sourced the final aligned weights on HuggingFace, which you can download here. We will also provide extensions for using our model with A1111 and ComfyUI in the near future. Finally, we release our work with a license that makes it easy for research teams to use what we’ve built. Given how much we have benefited from the research and open source communities, it was important that we make multiple aspects of our work for Playground v2.5 available publicly. We’re excited to see what the community will build on top of our work.
In this post, we share highlights of the research direction we took for v2.5, as well as some of the results from user evaluations and benchmarks. For a deeper dive into our research process, our techniques, and our approach to user evaluation (including a new benchmark we’re releasing to the community), please see our detailed technical report.
Progress-to-date and Research Approach
Playground was built on the incredible contributions of the open source community, particularly the family of diffusion-based image models known as Stable Diffusion. We began to build a research team early on and released our first model fine-tune, Playground v1, in late March 2023. After bringing our 256xH100 cluster online in October 2023, we swiftly advanced towards training our first foundation model from scratch, and we released Playground v2 by December of the same year—less than three months later. Now, we are introducing Playground v2.5 in February 2024, just two months after v2, and work has already begun on v3. The speed of progress in the image generation research space is lightning fast, and we are excited to be a part of pushing the field forward. (And of course, we’re hiring.)
When we launched Playground v2, we open-sourced the model and shared its pre-training weights. Over the last two months, we’ve been pleased to see the community take up our work and reference it. For example, Playground v2 has amassed over 135,000 downloads on HuggingFace in just the last month and has been cited as a reference checkpoint in papers for other models, like Stable Cascade.
Despite this success, we identified certain limitations with the v2 iteration, and we developed Playground v2.5 to address these. Notably, we chose not to change the underlying SDXL architecture for this project. Our goal was to quickly improve several qualities in our existing Playground v2 model before beginning work on v3. Even with this architectural constraint, our evaluations and qualitative results are very positive.
Specifically, we tackled three critical issues: enhancing color and contrast, improving multi-aspect ratio generation, and improving human-centric fine details. These are particularly tricky areas for diffusion models and can be frustrating for many end users. More generally, we aimed to refine the model’s capabilities to produce more realistic and visually compelling outputs. Below, we share high-level summaries on how we tackled each of these issues.
Enhanced Color and Contrast
Latent diffusion models typically struggle to generate images with vibrant color and contrast. This has been a known limitation since SD1.5. For example, SDXL is incapable of generating a pure colored image, and fails to place subjects onto solid colored backgrounds.

Although SDXL makes dramatic improvements on aesthetic quality over previous iterations, we still notice it exhibits muted color and contrast.

This issue stems from the noise scheduling of the diffusion process. The signal-to-noise ratio of Stable Diffusion is too high, even when the discrete noise level reaches its maximum. Several published works attempt to fix this flaw, notably Offset Noise and Zero Terminal SNR. SDXL, in particular, adopts Offset Noise in the last stage of training, and we used a version of this method for Playground v2.
For Playground v2.5, we take a more principled approach and train our models from scratch with the EDM framework, proposed by Karras et al. The EDM framework brings significant advantages, which we outline in our technical report.
Here is a comparison between Playground v2 – trained using Offset Noise and DDPM noise schedule – and Playground v2.5. One can clearly see an enhancement in color and contrast between the two models.

For more details on our methodology and approach, please see our technical report.

Image created by Playground user with Playground v2.5

Image by Playground user Mike Rubin, with Playground v2.5

Image by Playground user patrick, with Playground v2.5
Improved Multi-Aspect Ratio Generation
The ability to generate images of various aspect ratios is an important feature in real-world applications of text-to-image models. However, common pre-training procedures for these models start by training only on square images in the early stages, with random or center cropping.
In theory, this should not pose a problem. A diffusion model like SDXL consisting of mostly convolution layers – mimicking a Convolutional Neural Network (CNN) – should work for any resolution at inference time due to the transition-invariant property of CNNs. Unfortunately, in practice, diffusion models do not generalize well to other aspect ratios when only trained on square images.
To combat this, SDXL tried a new aspect-ratio bucketing strategy proposed by NovelAI (more on this in our technical report). However, SDXL still learned the bias of certain aspect ratios in its conditioning, due to an unbalanced dataset distribution.
In Playground v2.5, one of our explicit goals was to make the model reliably produce high quality images at multiple aspect ratios, as we had seen from our users that this is a critical element for a high-quality production-grade model.


While we followed a bucketing strategy similar to SDXL’s, we carefully crafted the data pipeline to ensure a more balanced bucket sampling strategy. Our strategy avoids catastrophic forgetting and helps the model not bias towards one ratio or another. And users have already begun utilizing this characteristic with stunning effect.

Image created by Shaddy, with Playground v2.5

Image created by PolyCrumbs, with Playground v2.5

Image created by Playground user, with Playground v2.5
Human Preference Alignment
Humans are particularly sensitive to visual errors on human features like hands, faces, and torsos. An image with perfect lighting, composition, and style will likely be voted as low-quality if the face of the human is malformed or the structure of the body is contorted.
Generative models, both language and image, are liable to hallucination. In image models, this can manifest as malformed human features. One of our goals with Playground v2.5 was to reduce the likelihood of visual errors in images of humans, which is a common critique of open-source diffusion models more broadly, as compared to closed-source models like Midjourney.
To address this, we developed a new alignment approach inspired by Emu, which introduced an alignment strategy similar to SFT for text-to-image generative models (SFT is a common strategy in LLMs to align a model with human preference and reduce errors).
Our novel alignment strategy enables us to excel over SDXL in at least four important human-centric categories:
- Facial detail, clarity, and liveliness
- Eye shape and gaze
- Hair texture
- Overall lighting, color, saturation, and depth-of-field
We choose to focus on these categories based on usage patterns in our product and from user feedback.

Image created by EMonz, with Playground v2.5

Image created by voisard, with Playground v2.5

Image created by 김철호, with Playground v2.5
User Evaluations
Since we ultimately build our models to be used by hundreds of thousands of users each month, it is critical for us to understand their preferences on model outputs. To this end, we conduct our user studies directly within our product. We believe this is the best context to gather preference metrics and provides the harshest test of whether a model actually delivers on making something valuable for an end user.
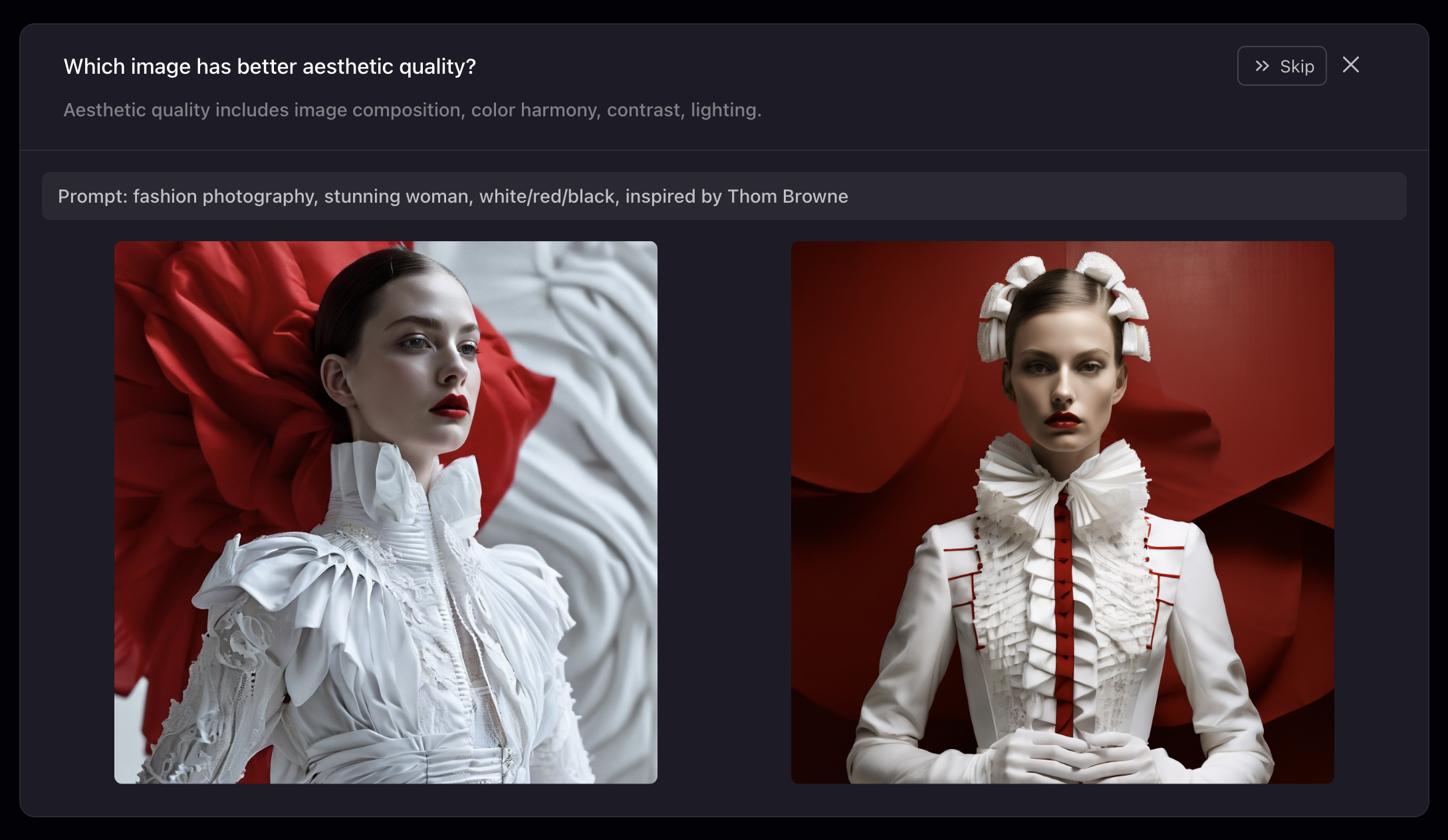
For more details on how we conduct these studies to reduce bias and ensure robustness, as well as the full set of results, please see our technical report.
But in short, we conducted studies to measure for overall aesthetic quality, as well as for the specific areas we aimed to improve with Playground v2.5, namely multi-aspect ratios and human preference alignment.
Across the board, the aesthetic quality of Playground v2.5 dramatically outperforms the current state-of-the-art open source models SDXL (by 4.8x) and PixArt-α (by 2.4x), as well as Playground v2. Because the performance differential between Playground V2.5 and SDXL was so large, we also tested against world-class closed-source models like DALL·E 3 and Midjourney v5.2, and found that Playground v2.5 still outperforms them.
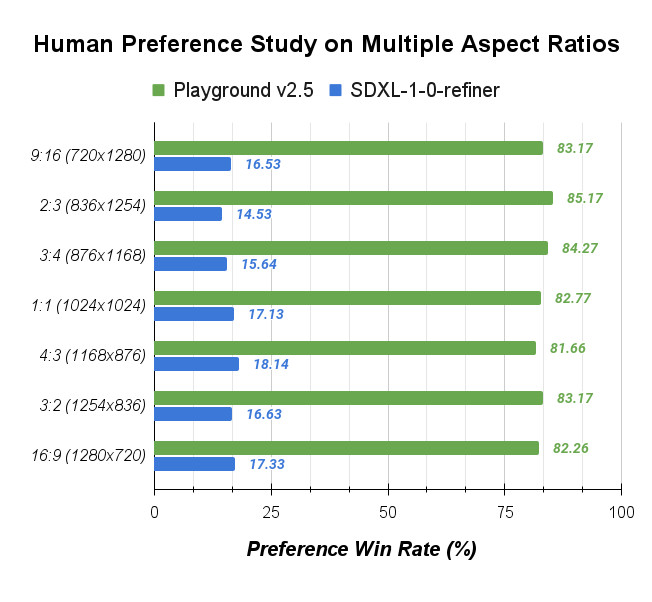
Similarly, for multi-aspect ratios, we outperform SDXL by a large margin.
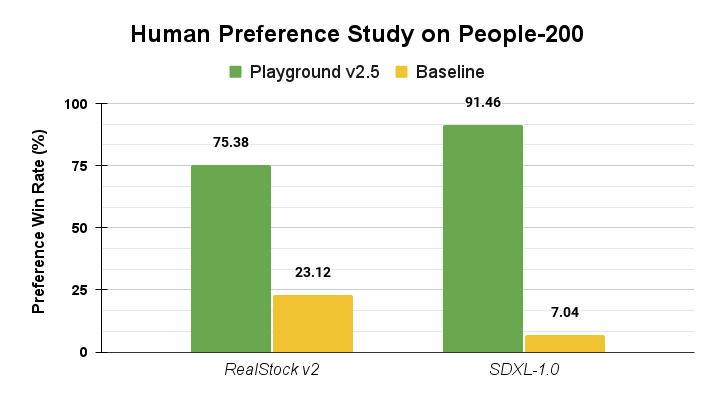
Next, we benchmark Playground v2.5 specifically on people-related images, to test Human Preference Alignment. We compared Playground v2.5 against two commonly-used baseline models: SDXL and RealStock v2, a community fine-tune of SDXL that was trained on a realistic people dataset.
Playground v2.5 outperforms both baselines by a large margin.
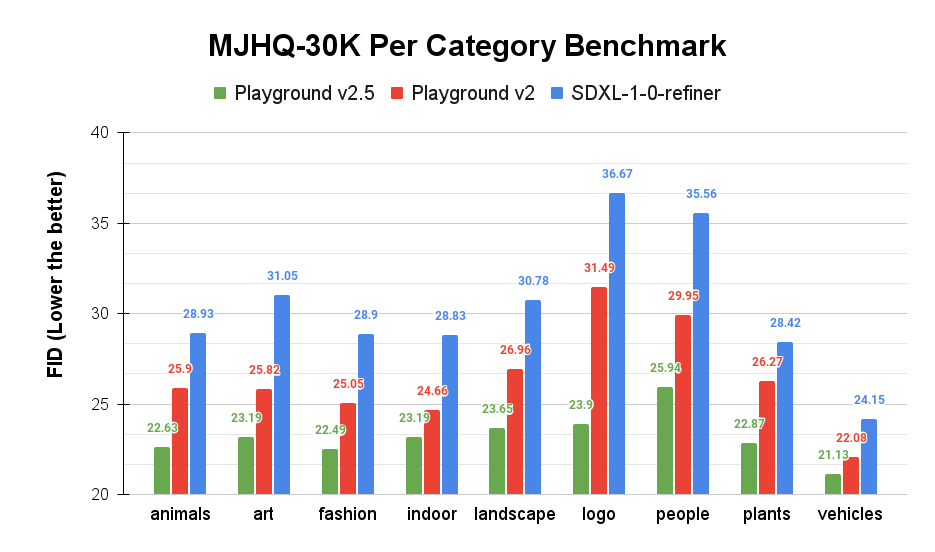
Lastly, we report metrics using our MJHQ-30K benchmark which we open-sourced with the v2 release, link here. We report both the overall FID and per category FID. All FID metrics are computed at resolution 1024x1024.
Our results show that Playground v2.5 outperforms both Playground v2 and SDXL in overall FID and all category FIDs, especially in the people and fashion categories. This is in line with the results of the user study, which indicates a correlation between human preferences and the FID score of the MJHQ-30K benchmark.
What’s next
The Playground Research team feels grateful for the swift progress we’ve been able to make in the last six months, in part from leveraging exciting new research from the community.
And yet, we are still only scratching the surface. There is so much room to improve. For our next project, our team is excited to explore new ideas. We will be re-evaluating every component of the model architecture, the data pipeline, and the training methodology from first principles. Some examples of challenges we hope to tackle next are: improving text-image alignment, enhancing the model’s variation capabilities, and exploring ways to enhance (or depart from) the latent space. We’re also looking to focus more on precise image editing.
If any of this sounds interesting to you and you want to be a part of shaping the future of computer vision and image generation, come join us. Please visit playground.com/jobs, or reach out to the team individually.
Authors: Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, Suhail Doshi
Contributors: Chase Lambert, Amelia Salyers